记录模块torch.nn.Parameter、torch.nn.Module、torch.autograd.Function,和常见的函数。
torch.nn.Parameter和torch.nn.Module
Parameter和Module的官方说明
torch.nn.Parameter:
Arguments: data=None, requires_grad=True.
torch.nn.Module:double() float() half() Casts all floating point parameters and buffers to double/float/half datatype.type(dst_type) Casts all parameters and buffers to dst_type.
cpu() cuda(device=None) Moves all model parameters and buffers to the CPU/GPU.
eval() train(mode=True) Sets the module in evaluation/training mode.
add_module(name, module) Adds a child module to the current module. The module can be accessed as an attribute using the given name.
apply(fn) Applies fn recursively to every submodule (as returned by .children()) as well as self.
extra_repr() Set the extra representation of the module. To print customized extra information, you should reimplement this method in your own modules. Both single-line and multi-line strings are acceptable.
forward(*input) Defines the computation performed at every call.
register_backward_hook(hook) Registers a backward hook on the module. The hook will be called every time the gradients with respect to module inputs are computed.register_forward_hook(hook) Registers a forward hook on the module. The hook will be called every time after forward() has computed an output.register_forward_pre_hook(hook) Registers a forward pre-hook on the module. The hook will be called every time before forward() is invoked.
requires_grad_(requires_grad=True) Change if autograd should record operations on parameters in this module. This method sets the parameters’ requires_grad attributes in-place.
to(*args, **kwargs) Moves and/or casts the parameters and buffers.
zero_grad() Sets gradients of all model parameters to zero.
buffers(recurse=True) Returns an iterator over module buffers.parameters(recurse=True) Returns an iterator over module parameters.named_buffers(prefix='', recurse=True) Returns an iterator over module buffers, yielding both the name of the buffer as well as the buffer itself.named_parameters(prefix='', recurse=True) Returns an iterator over module parameters, yielding both the name of the parameter as well as the parameter itself.register_buffer(name, tensor) Adds a persistent buffer to the module. This is typically used to register a buffer that should not to be considered a model parameter. Buffers can be accessed as attributes using given names.register_parameter(name, param) Adds a parameter to the module. The parameter can be accessed as an attribute using given name.load_state_dict(state_dict, strict=True) Copies parameters and buffers from state_dict into this module and its descendants. If strict is True, then the keys of state_dict must exactly match the keys returned by this module’s state_dict() function.state_dict(destination=None, prefix='', keep_vars=False) Returns a dictionary containing a whole state of the module. Both parameters and persistent buffers (e.g. running averages) are included. Keys are corresponding parameter and buffer names.
children() Returns an iterator over immediate children modules.modules() Returns an iterator over all modules in the network. Duplicate modules are returned only once.named_children() Returns an iterator over immediate children modules, yielding both the name of the module as well as the module itself.named_modules(memo=None, prefix='') Returns an iterator over all modules in the network, yielding both the name of the module as well as the module itself. Duplicate modules are returned only once.
Module中的parameters和buffers和state_dict
Pytorch模型中的parameter与buffer
parameter 反向传播需要被optimizer更新, 通过model.parameters()返回;buffer 反向传播不需要被optimizer更新,通过model.buffers()返回。
创建parameter:
(1) 直接将模型的成员变量(self.xxx)通过nn.Parameter()创建,会自动注册到parameters中,并且这样创建的参数会自动保存到state_dict中;
(2) 通过nn.Parameter()创建普通Parameter对象,不作为模型的成员变量,然后将Parameter对象通过register_parameter()进行注册,注册后的参数也会自动保存到state_dict中。
创建buffer:
需要创建tensor,然后将tensor通过register_buffer()进行注册,注册完后参数也会自动保存到state_dict中去。
1 | class MyModel(nn.Module): |
Module中的children和modules
1 | class MyModel(nn.Module): |
torch.autograd.Function
1 | # 示例 |
STATIC backward(ctx, *grad_outputs) It must accept a context ctx as the first argument, followed by as many outputs did forward() return, and it should return as many tensors, as there were inputs to forward(). Each argument is the gradient w.r.t the given output, and each returned value should be the gradient w.r.t. the corresponding input.
The context can be used to retrieve tensors saved during the forward pass. It also has an attribute ctx.needs_input_grad as a tuple of booleans representing whether each input needs gradient. E.g., backward() will have ctx.needs_input_grad[0] = True if the first input to forward() needs gradient computated w.r.t. the output.
STATIC forward(ctx, *args, **kwargs) It must accept a context ctx as the first argument, followed by any number of arguments (tensors or other types). The context can be used to store tensors that can be then retrieved during the backward pass.
torch.Tensor
torch.Tensor: class, is an alias for the default tensor type (torch.FloatTensor). A tensor can be constructed from a Python list or sequence using the torch.tensor() constructor:
1 | torch.tensor([[1., -1.], [1., -1.]]) |
item()
x.item() Returns the value of this tensor as a standard Python number. This only works for tensors with one element. This operation is not differentiable.
1 | x = torch.tensor([[1]]) |
clone()和detach()
x.clone() Returns a copy of the self tensor. The copy has the same size and data type as self. Unlike copy_(), this function is recorded in the computation graph. Gradients propagating to the cloned tensor will propagate to the original tensor. 开辟新的内存。x.detach() Returns a new Tensor, detached from the current graph. The result will never require gradient. Returned Tensor shares the same storage with the original one.
【Pytorch】对比clone、detach以及copy_等张量复制操作
contiguous()
Returns a contiguous tensor containing the same data as self tensor. If self tensor is contiguous, this function returns the self tensor.
PyTorch中的contiguous
index_add_(dim, index, tensor) → Tensor
Accumulate the elements of tensor into the self tensor by adding to the indices in the order given in index.
For example, if dim == 0 and index[i] == j, then the i th row of tensor is added to the j th row of self.
dim: int, dimension along which to index.
index: LongTensor, indices of tensor to select from.
tensor: Tensor, the tensor containing values to add.
1 | x = torch.ones(5, 3) |
torchvision.transforms
Transforms on PIL Image: 输入为PIL Image,输出也为PIL Image。
torchvision.transforms.ToTensor: Convert a PIL Image or numpy.ndarray to tensor.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) or if the numpy.ndarray has dtype = np.uint8.
1 | # PIL.Image读的图片为 W*H,通道为 RGB |
Loss functions
NLLLoss
CLASS: torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
FUNCTION: torch.nn.functional.nll_loss(input, target, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
The negative log likelihood loss. It is useful to train a classification problem with C classes.
size_average: Deprecated.
reduce: Deprecated.
weight: a manual rescaling weight given to each class. If given, it has to be a Tensor of size $C$. Otherwise, it is treated as if having all ones. This is particularly useful when you have an unbalanced training set.
ignore_index: Specifies a target value that is ignored and does not contribute to the input gradient. When reduction='mean', the loss is averaged over non-ignored targets.
reduction: Specifies the reduction to apply to the output: 'none' | 'mean' | 'sum'.
input: log-probabilities of each class, Tensor of size either $(N,C)$ or $(N,C,d_1,d_2,\ldots,d_K)$ with $K\geq1$ for the K-dimensional case.
Obtaining log-probabilities in a neural network is easily achieved by adding a LogSoftmax layer in the last layer of your network. You may use CrossEntropyLoss instead, if you prefer not to add an extra layer.
target: class index in the range $[0,C-1]$; if ignore_index is specified, this loss also accepts this class index (this index may not necessarily be in the class range). Tensor of size either $(N)$ or $(N,d_1,d_2,\ldots,d_K)$ with $K\geq1$ for the K-dimensional case.
Output: scalar. If reduction is ‘none’, then the same size as the target: $(N)$ or $(N,d_1,d_2,\ldots,d_K)$ with $K\geq1$ for the K-dimensional case.
reduction='none', loss: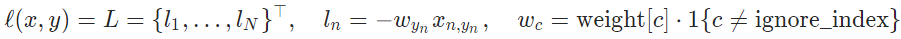
reduction='mean'or reduction='sum', loss: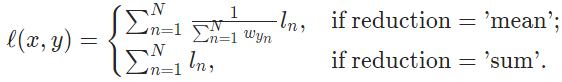
In the K-dimensional case, it computes NLL loss per-pixel.
1 | import torch |
CrossEntropyLoss
CLASS: torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
This criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class.
The input is expected to contain raw, unnormalized scores for each class.

BCEWithLogitsLoss
CLASS: torch.nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None)
This loss combines a Sigmoid layer and the BCELoss in one single class.
size_average: Deprecated.
reduce: Deprecated.
weight: a manual rescaling weight given to the loss of each batch element. If given, has to be a Tensor of size nbatch.
reduction: Specifies the reduction to apply to the output: 'none' | 'mean' | 'sum'.
pos_weight: a weight of positive examples. Must be a vector with length equal to the number of classes.
Input: (N, #).
target: (N, #), numbers between 0 and 1.
Output: scalar. If reduction is ‘none’, then (N, #), same shape as input.
reduction='none', loss: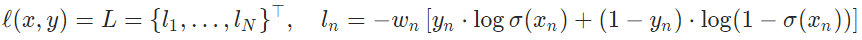
reduction='mean'or reduction='sum', loss: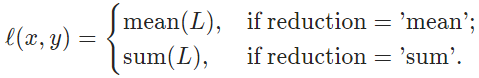
It’s possible to trade off recall and precision by adding weights to positive examples. multi-label classification:
torch.nn.functional
torch.nn.functional.normalize(input, p=2, dim=1, eps=1e-12, out=None)
Performs $L_p$ normalization of inputs over specified dimension.
$$
v=\frac{v}{\max(||v||_p, \epsilon)}
$$
1 | import torch |
x.norm(p='fro', dim=None, keepdim=False, dtype=None)torch.norm(input, p='fro', dim=None, keepdim=False, out=None, dtype=None)
Returns the matrix norm or vector norm of a given tensor.
1 | a = torch.tensor([1,2,2], dtype=torch.float) |