Unsupervised domain adaptive re-identification: Theory and practice
https://github.com/LcDog/DomainAdaptiveReID
Liangchen Song, Cheng Wang, Lefei Zhang, et al.
Wuhan University, Horizon Robotics, Huazhong University of Science and Technology.
将分类任务中的无监督域自适应理论扩展到re-ID,在特征空间上引入一些假设,并根据这些假设导出损失函数,提出了self-training框架最小化损失函数。
理论
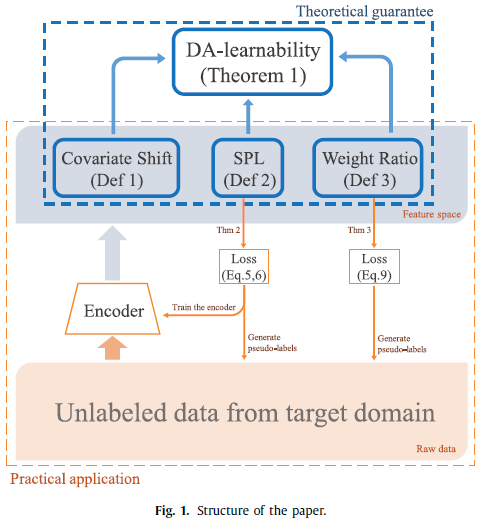
In the context of re-ID tasks, two questions are of concern:
1.Under what conditions are unsupervised domain adaptive re-ID tasks DA-learnable?
2.How does the theoretical conditions help practical algorithms?
对于问题1,根据论文[1]对分类任务做的3个假设,提出re-ID中的3个假设:
- covariate assumption: the criteria of classifying feature pairs is the same between two domains;
- Separately Probabilistic Lipschitzness: the feature pairs can be divided into clusters;
- weight ratio: concerning the probability of existing a repeated feature among all the features from the two domains.
Based on the three assumptions, we then show the DA-learnability of unsupervised domain adaptive re-ID tasks.
对于问题2,提出self-training框架来训练encoder。Concretely, we iteratively refine the encoder by making guesses on unlabeled target domain and then train the encoder with these samples.
根据上述假设, we propose several loss functions on the encoder and samples with guessed label. And the problem of selecting which sample with guessed label to train is optimized by minimizing the proposed loss functions.
For the Separately Probabilistic Lipschitzness assumption, we wish to minimize the intra-cluster and maximize inter-cluster distance. Then the sample selecting problem is turned into data clustering problem and minimizing loss functions is transformed into finding a distance metric for the data.
Further, another metric for Weight Ratio is designed.
After combining the two metrics together, we end up with a distance evaluating the confidence of the guessed labels.
Finally, the DBSCAN clustering method is employed to generate data clusters according to a threshold on the distance. With pseudo-labels on selected data cluster from target domain, the encoder is trained with triplet loss.
实现

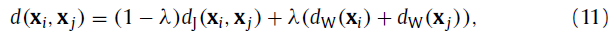
假设2和3最后实现时转变成设计distance metric,用k-reciprocal encoding计算距离,再用DBSCAN进行聚类,DBSCAN参数中的阈值是根据距离取的,最后根据选择的数据的伪标签用triplet loss训练。
[1] S.Ben-David, R.Urner. Domain adaptation-can quantity compensate for quality? Ann. Math. Artif. Intell. 70 (3) (2014) 185–202.